Iteris is an agentic research system for computational mathematics, the branch of mathematics concerned with algorithmic design and analysis. We applied it to open problems from the Simons Workshop collection (Amsel et al., 2026) and obtained two author-verified results: a phase diagram for the asymptotic comparison between conjugate gradient and randomized coordinate descent, and a counterexample showing that QR with column pivoting can select badly conditioned submatrices even on well-balanced inputs. These are early results on two specific problems, not a general capability claim. The rest of this post describes the system, the two case studies, and what human mathematical judgment contributed at each stage.
System Design: Explore, Plan, Execute
Most AI-for-math systems target a specific research mode. Proof-search systems focus on deductive reasoning: given a conjecture, find a proof. Program-search systems optimize a single evaluable objective: generate candidates, score them, and keep improving. Both patterns are powerful when the research question fits their shape, and both have produced impressive results on well-defined targets.
Computational mathematics rarely begins with a fixed conjecture or a single score to optimize. Instead, the research question often emerges from the work itself. A project may start with numerical sweeps that suggest what is worth proving, not just confirm what was already guessed. It may require comparing algorithms across parameter regimes that can only be discovered experimentally, so the “right” method depends on where you are in the landscape. And it may call for explicit counterexamples whose point is to explain why a method fails and what to build next.
Theory, experiment, and algorithm design therefore advance together in a loop: each round refines the others. The aim is not simply to obtain a theorem, but to understand algorithmic behavior deeply enough to improve practice.
Iteris is designed for this mixed-mode workflow. Its architecture is an explore-plan-execute loop, iterated over many rounds. The loop coordinates numerical exploration, proof construction, adversarial search, and critical review inside one auditable trajectory.
The following subsections trace the logic: why exploration and planning must be separated, why execution needs distinct research modes, and how durable file-based state holds a hundred-iteration trajectory together.
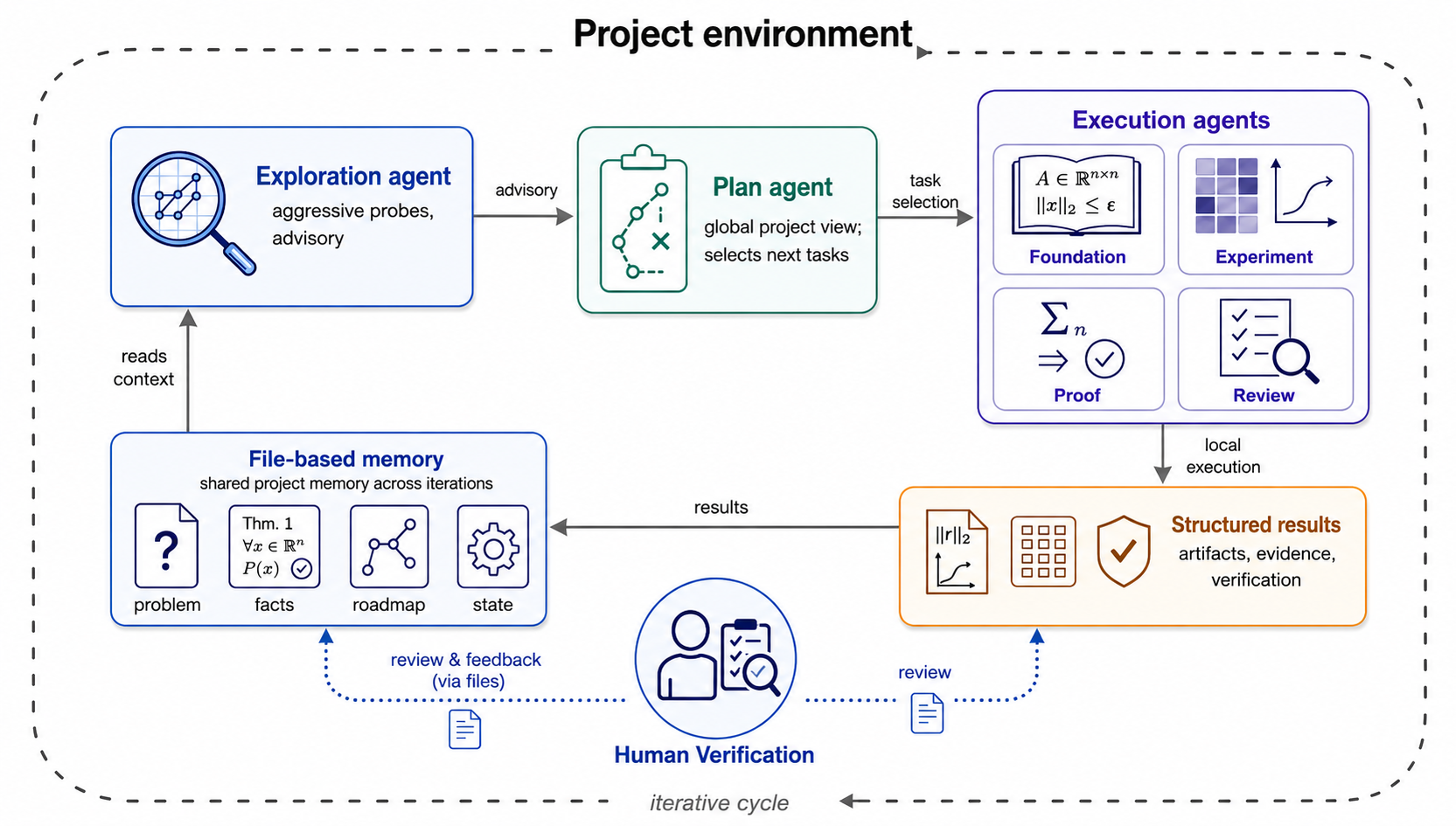
Explore before committing to a plan
The plan agent reads the full project state (problem statement, roadmap, prior facts, frontier state) and decides the next task pool. This global view keeps the project coherent across iterations.
But the same coherence may create inertia. If a branch looks natural, the plan agent may keep refining it even when the project needs a lateral move. Consider a hypothetical scenario: the plan agent has locked onto a particular spectral regime and keeps scheduling incremental refinements there, while the actual phase transition happens in a different regime entirely.
The exploration agent is separated from the plan agent to reduce this risk. It runs lightweight probes before the next plan is committed: reading recent artifacts, checking whether the current route has narrowed into incremental follow-up, comparing plausible alternatives. The exploration agent does not set the task pool. It produces advisory signals that the plan agent can accept, modify, or override.
This separation matters most when the project needs to change direction. If the same agent both explores and plans, the sunk cost of the current route biases the exploration. A separate exploration agent can evaluate alternatives without the plan agent’s commitment to the current branch.
Separate research modes
Computational mathematics alternates between different kinds of work, and confusing them creates false progress. Numerical evidence is informative but is not a proof. A route can look productive until a review agent asks what has actually been established. Iteris therefore uses four execution agents, chosen per iteration by the plan agent:
- Foundation agents audit sources, freeze definitions, draft conjecture cards, and maintain claim discipline.
- Experiment agents run numerical tests, diagnostics, parameter sweeps, and counterexample searches.
- Proof agents construct proof artifacts for scoped mathematical targets.
- Review agents evaluate evidence, proof gaps, route value, and claim status.
Each agent receives a scoped task and writes structured result files. This keeps numerical evidence, proof modules, reviewed facts, and theorem-level claims distinct, which matters because confusing evidence with proof is one of the most common ways a long research project goes wrong.
In our experiments, the generation agents were implemented using OpenAI Codex with GPT-5.5 as the underlying model.
Files as memory and messages
All project state lives in files: problem statements, route decisions, reviewed facts, experimental results, proof artifacts, and task pools. Files serve two roles. They are memory because they keep state stable across iterations. They are also messages because they move structured information from one agent to the next.
This matters because the research trajectories in our case studies were long. Without durable state, a review agent in a later iteration cannot check whether the route it is evaluating was already attempted and rejected in a previous iteration. An agentic loop can sound coherent while repeatedly forgetting what has already failed.
The file-based design also makes human oversight practical. A mathematician joining the project mid-stream can read the route decisions, reviewed facts, and obstruction records to understand what has been tried and why. This is important for the human-AI collaboration model described later in the post: the human does not need to monitor every iteration, but can review the trajectory at key decision points and intervene when mathematical judgment is needed.
With the file-based architecture, all three components of the loop (exploration, planning, execution) operate on the same shared state. The exploration agent reads the same files the plan agent reads. The review agent’s output becomes input for the next planning cycle. This shared-state design is what makes a hundred-iteration trajectory coherent rather than a random walk.
The Problems: Two Modes of Algorithmic Analysis
The Simons Workshop collection Linear Systems and Eigenvalue Problems: Open Questions from a Simons Workshop (Amsel et al., 2026) compiles genuine open questions from numerical linear algebra and scientific computing. The two problems below represent two canonical modes of computational mathematics research: building a phase diagram and constructing a counterexample.
Problem 1: When is one algorithm better than another? Conjugate gradient (CG) and randomized coordinate descent (RCD) both solve linear systems, but they use information very differently. CG builds global Krylov subspaces and exploits the full spectrum of the matrix; it sees the whole problem at once, but each step is expensive. RCD updates one coordinate at a time: each step is cheap, but many more steps may be needed. The natural comparison unit is an epoch ($n$ coordinate updates in dimension $n$), which equalizes the per-iteration cost difference.
The open problem (Problem 2.4 in the Simons collection) asks how epoch-normalized RCD stopping time compares to CG stopping time when the matrix has power-law eigenvalue decay controlled by a parameter $p$, and the target accuracy is $\epsilon$. This is a question about understanding algorithmic behavior across a continuous family of problem instances.
Problem 2: Does a classical algorithm always do what we expect? QR factorization with column pivoting (QRCP) is a widely used greedy method for rank detection and column selection. At each step, it greedily selects the column with the largest residual norm. In an orthonormal setting, this greedy rule seems well-motivated, and it is natural to expect that the selected rows form a well-conditioned submatrix. The open question (Problem 4.3 in the Simons collection) is whether that expectation is actually justified, or whether QRCP can be forced to select a badly conditioned block.
Both problems are about understanding algorithmic behavior. One asks for a map of parameter regimes; the other asks for a guarantee or a refutation. Together, they exercise the two research modes that Iteris was designed to coordinate: sustained analytical decomposition and adversarial construction guided by failed proofs. They also share a common structure: both are about understanding algorithmic behavior deeply enough to make precise mathematical claims.
We describe the two case studies below. The first illustrates how the explore-plan-execute loop decomposes a broad analytical question into tractable proof targets. The second illustrates a different trajectory: a failed proof attempt that becomes the blueprint for an exact counterexample.
Case Study I: A Phase Diagram for CG vs. RCD
We work in the Simons Problem 2.4 setup.
For fixed $p \gt 0$ and target accuracy $\epsilon \in (0,1)$, draw $A_n = U_n \operatorname{diag}(1^{-p}, 2^{-p}, \ldots, n^{-p}) U_n^\ast$ with Haar-uniform $U_n$, set $b_n = A_n z_n$ for a uniform unit vector $z_n$ (so the exact solution is $x_{\ast,n} = z_n$), and run unpreconditioned CG and coordinate RCD from $x_0 = 0$. Let $T_{\mathrm{CG},n}(\epsilon,p)$ and $T_{\mathrm{RCD},n}(\epsilon,p; I)$ denote the first step at which each method reaches relative $A_n$-error $\le \epsilon$. To compare fairly, RCD is measured in epochs ($n$ coordinate updates), and we study the ratio $$\rho_n(\epsilon,p) = \frac{T_{\mathrm{RCD},n}(\epsilon,p; I)/n}{T_{\mathrm{CG},n}(\epsilon,p)}.$$ The question is not simply which method wins, but how $\rho_n$ behaves as $n \to \infty$ across the $(p,\epsilon)$ plane, a phase diagram rather than a single answer.
Iteris mapped this phase diagram. The structure is richer than a simple “CG wins” or “RCD wins” answer.
For $p \gt 1/3$, RCD measured in epochs becomes asymptotically negligible compared with CG steps at any fixed accuracy target. Intuitively, when the spectrum decays fast enough, CG’s ability to exploit global spectral structure gives it a decisive advantage that cheap coordinate updates cannot overcome.
For $0 \lt p \lt 1/3$, the answer depends on where the target accuracy $\epsilon$ lies relative to a floor $F(p)$ that comes from the limiting CG approximation problem. Above this floor, CG still dominates; below it, the comparison reverses. The boundary case $p = 1/3$ is handled separately in the paper.
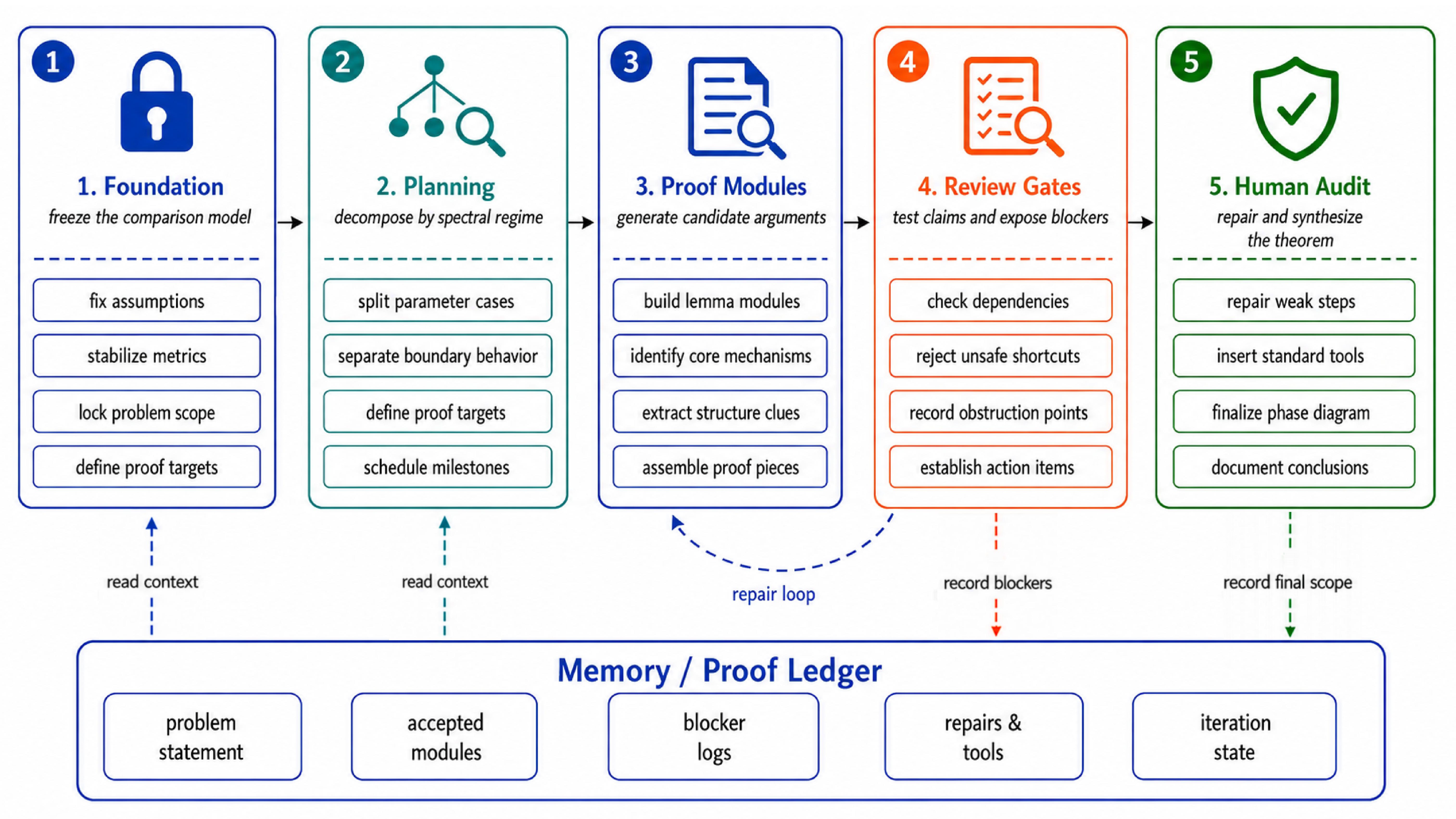
The research trajectory. The project moved through five phases over roughly a hundred iterations.
Foundation. Foundation agents froze the comparison model: Haar-distributed eigenvectors, power-law eigenvalues, fixed source distribution, exact unpreconditioned CG, and RCD measured in epochs. This step may sound bureaucratic, but it prevented a failure mode that appeared repeatedly in early experiments: later agents silently changed the solver variant, the randomness model, or the unit of comparison, invalidating previous proof modules without notice.
Planning. The plan agent decomposed the problem by spectral regime ($p \gt 1$, $p = 1$, $0 \lt p \lt 1$). This split matters because these ranges correspond to qualitatively different spectral behavior; for example, $p = 1$ is a logarithmic boundary between summable and nonsummable regimes. In the nonsummable range $0 \lt p \lt 1$, the project further split according to where $\epsilon$ sits relative to the phase boundary.
This hierarchical decomposition turned one broad comparison into smaller proof targets with explicit dependencies. Each target could be assigned to a proof agent with a scoped task, and the plan agent tracked which targets had been completed, which were blocked, and which remained open.
Proof modules. Proof agents generated modular components for CG residual polynomials, RCD epoch bounds, and the limiting moment problem.
Review gates. Review agents played an equally important role. They blocked shortcuts that looked plausible but were not justified, including attempts to upgrade fixed-degree non-stopping statements into growing-degree rate bounds. In computational mathematics, this negative information is valuable: knowing which route is unsupported prevents a heuristic from hardening into a false theorem. The review gates also maintained a record of rejected routes, so the plan agent could avoid revisiting dead ends in later iterations.
Human audit. The initial agentic trajectory emphasized the qualitative phase diagram: which algorithm wins in which regime. The sharper rate question (how fast does the ratio converge in regimes where it goes to zero?) was introduced by human mathematical judgment. This is a case where human insight set a more ambitious target than the system would have pursued on its own.
Once that target was explicit, early candidate proofs suggested a stronger rate than the available estimates justified. Human inspection identified the gap between the proof technique and the claimed quantitative conclusion. Later human-AI interaction replaced the overstrong claim with conservative bounds actually supported by the proof. The final theorem states honest upper bounds rather than sharp rates. A correct conservative bound is worth more than an attractive but unjustified sharp claim.
Case Study II: A QRCP Counterexample
The CG/RCD case study illustrates the analytical decomposition mode: break a broad question into spectral regimes, generate modular proof components, and let review agents enforce claim discipline. The QRCP case study illustrates a different trajectory entirely: a failed proof becomes the blueprint for an adversarial construction.
QR factorization with column pivoting is a greedy method. At each step, it selects the remaining column with the largest residual norm after projecting away the previously selected columns. The rule is simple, deterministic, and widely used. The open problem asks whether this local greedy rule reliably selects a well-conditioned subset in an orthonormal setting.
More precisely: let $Q$ be an $n \times k$ matrix with orthonormal columns, so $Q^\top Q = I_k$. Applying QRCP to $Q^\top$ means the columns being pivoted are exactly the rows of $Q$. The algorithm selects $k$ rows; write $M = Q[I, :]$ for the selected block. A large $\|M^{-1}\|_2$ means the selected block is poorly conditioned. The natural comparison scale in this problem is $\sqrt{k(n - k + 1)}$. The question is whether QRCP always keeps $\|M^{-1}\|_2$ controlled at that scale, or whether the greedy pivot rule can accumulate errors that compound into poor global conditioning.
This is a question with practical implications: QRCP is used throughout numerical linear algebra, and understanding its guarantees (or lack thereof) matters for the design of reliable computational methods.
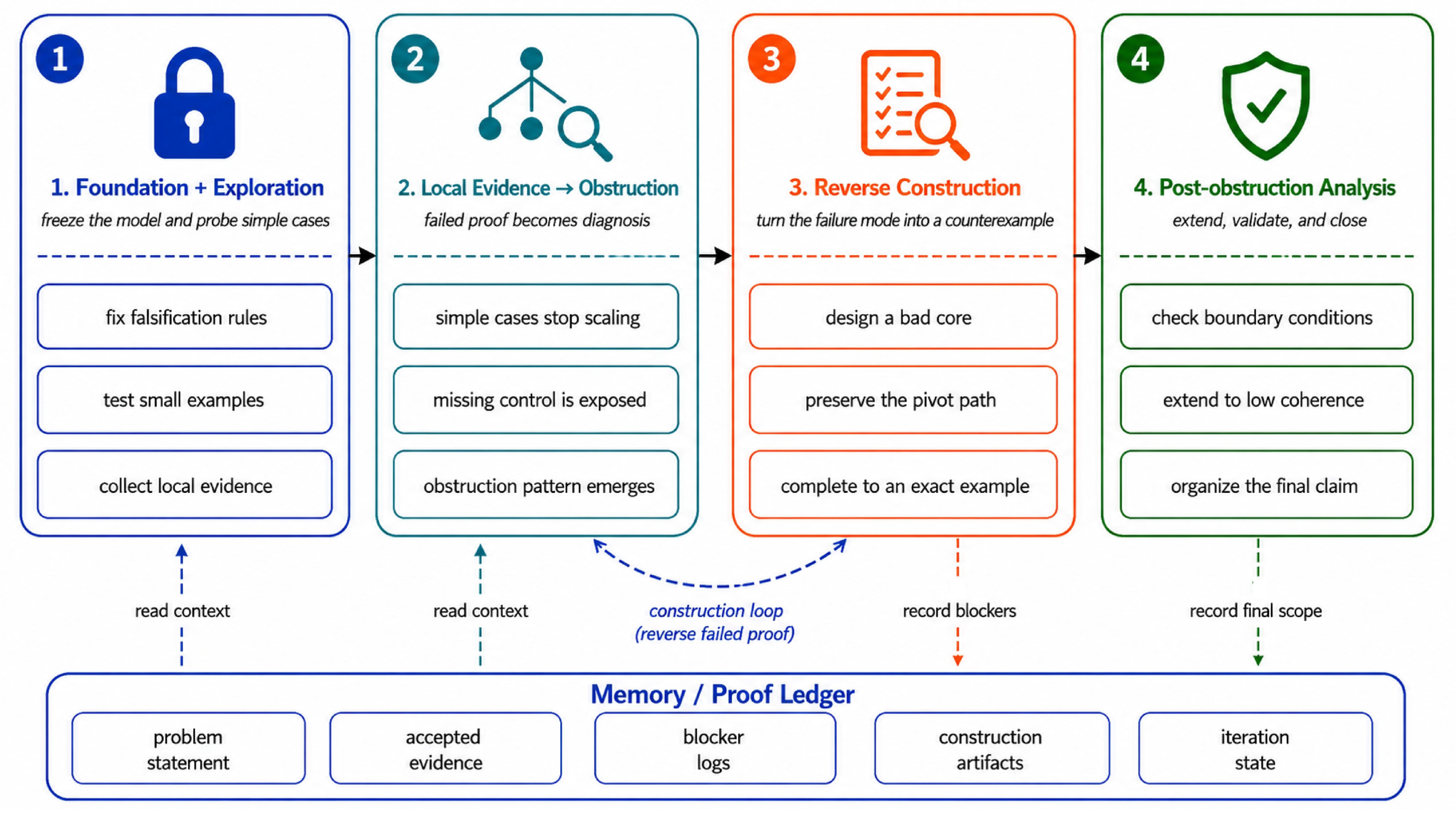
The answer is no. The Iteris-assisted workflow produced a negative answer: for arbitrarily large polynomial factors, one can construct an orthonormal system with bounded coherence such that QRCP selects a badly conditioned submatrix. Bounded coherence means the row energies are not dominated by a few unusually large rows. This rules out the most obvious rescue hypothesis: QRCP is not being tricked merely by a handful of high-leverage outliers.
The trajectory. The interesting part is not only the counterexample but how it was found. The project moved through four phases, again over roughly a hundred iterations.
Iteris first attempted to prove the positive statement. Foundation agents fixed the falsification rules and tested small cases. Those early proof attempts failed at $k = 3$. Crucially, the way they failed was diagnostic: they revealed that local residual norms and orthogonality do not control the cross-interaction among QRCP-selected rows. QRCP can know which column currently looks largest without protecting the global conditioning of the block it is building.
The failed proof was then reversed into a construction target. Build a selected core that satisfies the local pivot conditions but creates bad triangular back-substitution. Then complete the remaining rows so that the full matrix still comes from an orthonormal system, while keeping unused rows from stealing the QRCP pivots and keeping leverage scores controlled. Post-obstruction analysis extended the construction to low coherence and validated the final claim.
This is a different style of agentic contribution from the CG/RCD case. The system did not search randomly for a bad example. It turned a failed proof into a mechanism: local pivot control does not prevent global conditioning failure. The final construction came from iteratively repairing this mechanism until pivot control, orthonormality, conditioning, and coherence held simultaneously. Each repair required careful coordination, because fixing one constraint (say, ensuring the unused rows do not steal pivots) could break another (say, maintaining bounded coherence). The explore-plan-execute loop managed this multi-constraint repair process across many iterations.
The core theorem was also checked through a sorry-free Lean 4 formal proof of its formal counterpart, with the aid of Archon, our autoformalization agent. The QRCP verification artifact is available at frenzymath/qrcp-bounded-coherence-obstruction. This connects two systems in our research group at complementary stages of the pipeline: Iteris discovers and constructs mathematical results; Archon formally verifies them.
The Role of Human Judgment
Iteris shifts human effort; it does not remove it. In both case studies, the system broadened the search space, generated candidate structures, preserved blockers across iterations, and produced draft arguments for inspection. Humans guided the research direction and validated the mathematical claims.
The two case studies required different kinds of human intervention, and these tell us about where current systems are reliable and where they are not.
In the CG/RCD problem, the intervention was mathematical correction. The system generated a rate claim that was not supported by the available estimates. Human inspection detected the mismatch between the proof technique and the claimed quantitative conclusion. The result was then weakened to conservative bounds actually implied by the argument. This is a content-level intervention: the mathematics was wrong and needed to be fixed. Without human oversight, an attractive but unjustified sharp rate would have been reported as a theorem.
In the QRCP problem, the intervention was mostly narrative reorganization and semantic alignment. The construction mechanism was correct, but the generated proof trajectory was long and circuitous. Turning it into a readable mathematical argument required substantial restructuring. After the Lean formalization, humans still had to verify that the formal theorem and the informal paper claim referred to the same object, assumptions, and scope. This is a presentation-level intervention: the mathematics was right but needed to be communicated clearly enough for others to verify and build on.
The distinction suggests where the current capability boundary lies: the system is more reliable at generating mathematical structures (phase decompositions, counterexample mechanisms) than at producing polished arguments with correct quantitative claims on the first try. Recognizing this boundary honestly is more useful than obscuring it, because it tells us exactly where human effort is most needed and where the system can be trusted to work with less supervision.
Closing
The capability boundary just described is precisely why computational mathematics is a natural target domain for agentic AI research systems. Because computational mathematics has two feedback channels (experiments that guide search and proofs that settle claims), an agentic system can iterate toward correct results even when its first-pass arguments are flawed. In domains where only deductive proof matters, a wrong first attempt has no corrective signal. In computational mathematics, numerical evidence and review agents can catch errors that the proof agent missed. The system’s strength at generating structures, combined with human strength at validating claims, creates a division of labor that fits the structure of the field.
The next steps are straightforward but demanding. Scaling to more open problems will test whether the explore-plan-execute loop generalizes beyond the two problems studied here. Tighter integration of numerical experimentation with proof construction should reduce the iteration count needed to converge on correct claims.
The most important direction is moving from analyzing the behavior of existing algorithms toward designing new ones. Both case studies in this post are analytical: given an existing algorithm, understand its performance landscape or find its failure modes. The harder and more valuable task is to use that understanding to build better methods.
These are early results. The two problems we studied are specific, the human role was substantial in both cases, and we do not know yet how the approach scales to harder problems or different areas of computational mathematics. But they suggest that agentic AI systems can participate meaningfully in long research workflows for computational mathematics, when human mathematical judgment guides the direction and validates the claims.
Iteris is an early step in that direction. Its strongest contribution is not replacing mathematical judgment, but making long mixed-mode research trajectories, the kind where numerical experiments, adversarial constructions, and proofs interact over hundreds of iterations, more productive and auditable.